Ai llm rag agi
Python
Build a LLM RAG that can answer local files.
公司希望對A.I.除了智慧製造專案外,能有其他方面的應用或是題目。 當然一開始是滿頭問號??節省人力,不是已經有RPA? 智慧製造也在嘗試"瑕疵檢測"方面的嘗試,怎麼生出其他A.I.題目?
基於2023.8我有篇文章"Build a Q&A bot that can answer local files."
- 不足的地方:
- 有Model,但沒有使用LLM
- 難以衍伸其他應用
- 沒有API
想想2023應該算是GPT方案大噴發的一年吧,公司怎麼可以沒沾個邊呢? 2023.Q4開始LLM冒險吧!
- 專案應該要些範圍:
- 開源LLM:所以不能使用chatgpt/openai
- 離網使用:公司文件不能外流
- 盡量API化
- 使用GPU,CPU算力不夠
(1)先看看LLM的執行效果
(2)原始csv長相這樣,

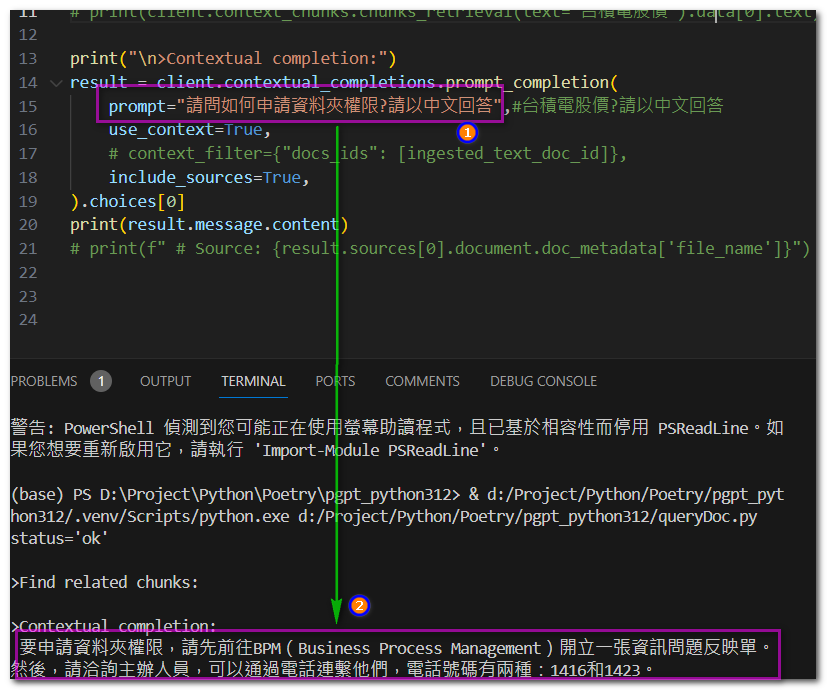
(3)code:除非你跟我一樣使用PrivateGPT API,否則請不要照抄
from pgpt_python.client import PrivateGPTApi
client = PrivateGPTApi(base_url="http://192.168.11.63:8001")
# Health
print(client.health.health())
# Chunks
print("\n>Find related chunks:")
# print(client.context_chunks.chunks_retrieval(text="台積電股價").data[0].text)
print("\n>Contextual completion:")
result = client.contextual_completions.prompt_completion(
prompt="請問如何申請資料夾權限?請以中文回答",#台積電股價?請以中文回答
use_context=True,
# context_filter={"docs_ids": [ingested_text_doc_id]},
include_sources=True,
).choices[0]
print(result.message.content)
# print(f" # Source: {result.sources[0].document.doc_metadata['file_name']}")
- 請避免採坑:
- 請務必確認使用CUDA,雖然很多LLM號稱CPU就夠,但實際上CPU算力是不夠的。
- LLM需支援API,否則我很難想像怎麼產品化?
- LLM的安全,沒做到?等者被爆
謝謝大家的閱讀!